GEO uyumlu içerik üretimi, büyük dil modellerinin içerik üretiminde ciddi bir kapasiteye sahip hale gelmesiyle ön plana çıktı. Ama çoğu kullanım, bu kapasiteden yalnızca küçük bir pay alıyor. Sorun araçların yetersizliğinde değil; büyük ölçüde hazırlık aşamasının atlanmasında. Bağlam verilmeden, model seçilmeden, hedef netleştirilmeden yapay zekaya içerik yazdırmak, kıdemli bir editöre “şu konuda bir şeyler yaz” demekten farklı değil.
Bu yazıda yapay zekayla kaliteli içerik üretmenin neresinden başlandığını, hangi hataların süreci raydan çıkardığını ve sistematik bir workflow’un bunu nasıl değiştirdiğini paylaşıyorum.
Yapay zeka içerik üretimi nedir?
Yapay zeka içerik üretimi, büyük dil modellerinin metin anlama ve üretme kapasitesini belirli bir hedef doğrultusunda kullanmaktır. Araştırma, yapı kurma ve yazım aşamalarının bir bölümünü veya tamamını yapay zeka desteğiyle yürüten bu süreç, içerik ekiplerinin üretim kapasitesini artırır; insan uzmanlığının yerini almaz.
Bu modeller, geniş veri setlerinden öğrendikleri dil örüntülerini, verilen bağlam ve talimatlarla birleştirerek içerik üretiyor. Anthropic‘in Claude modeli gibi güncel dil modelleri, yalnızca metin tahmini yapmıyor; argüman kurma, kaynak analizi ve bağlam oluşturma konularında belirgin bir yetkinliğe ulaşmış durumda.
Yapay zeka içerik üretimini basit bir kelime tamamlama motorundan ayıran şey bu yapısal düşünme kapasitesi. Sıradan bir yazı üretmek değil; bir konuyu araştırmak, alt başlıklarını planlamak, belirli bir sese uygun yazmak ve güncel bilgileri dahil etmek artık aynı iş akışı içinde mümkün.
Ama bu kapasite, kendiliğinden devreye girmiyor. İçerik kalitesini belirleyen, çıktının ne kadar “akıllı” göründüğü değil; modele ne kadar doğru bağlam ve hedef verildiği.
Yapay zekayı kıdemli bir editör gibi besleyin
Yapay zekadan kaliteli içerik almanın yolu, bağlam ve brief vermekten geçiyor. Kıdemli bir içerik editörüne “e-ticaret danışmanlığı nedir” deyip bir sayfa isteseydiniz, büyük olasılıkla beklediğiniz çıktıyı alamazdınız. Yapay zekada durum farklı değil.
Brief olmadan ne olur: bir vaka

Bir SEO uzmanının “yapay zeka ile içerik üretimi” konusunu tartıştığı bir görüşmeye tanıklık ettim. Uzman, süreci canlı göstermek için Gemini üzerinde bir deneme yaptı ve şu talimatı girdi: “E-ticaret danışmanlığı nedir hakkında bir blog yazısı yaz.”
Üç temel sorun göze çarpıyordu. Birincisi, hedef kitle, marka sesi veya içeriğin amacı belirtilmemişti; doğrudan konu verildi. İkincisi, Gemini kullanıcısı olmasına karşın en güçlü modeli değil, hız odaklı Flash modelini seçmişti; yani aynı sağlayıcının kapasitesi kasıtlı olarak düşürüldü. Üçüncüsü, rakip bağlamı ve hedef kitle hiç aktarılmadı.
Yapay zeka yine de bir şey üretti; üretir. Bazı modeller netlik için geri bildirim ister, ama bu her modelde ve her çalışmada geçerli değil. Çıktı genel, yüzeysel ve o markayla hiçbir bağı olmayan bir içerikti. İçerik stratejisi ve içerik üretimi seo uzmanlığının önemli bir alanı olsa da yazarlarla doğrudan çalışmadan sürecin nasıl işlediğini bilmek mümkün değil; bu vaka da tam bunu gösteriyordu.
Aynı senaryoyu kıdemli bir editörle kurun: bağlam yok, hedef yok, marka sesi yok. Sonuç farklı olmaz. Çıktının kalitesi, aracın değil; verilen hazırlığın kalitesidir.
Brief ne içermeli?
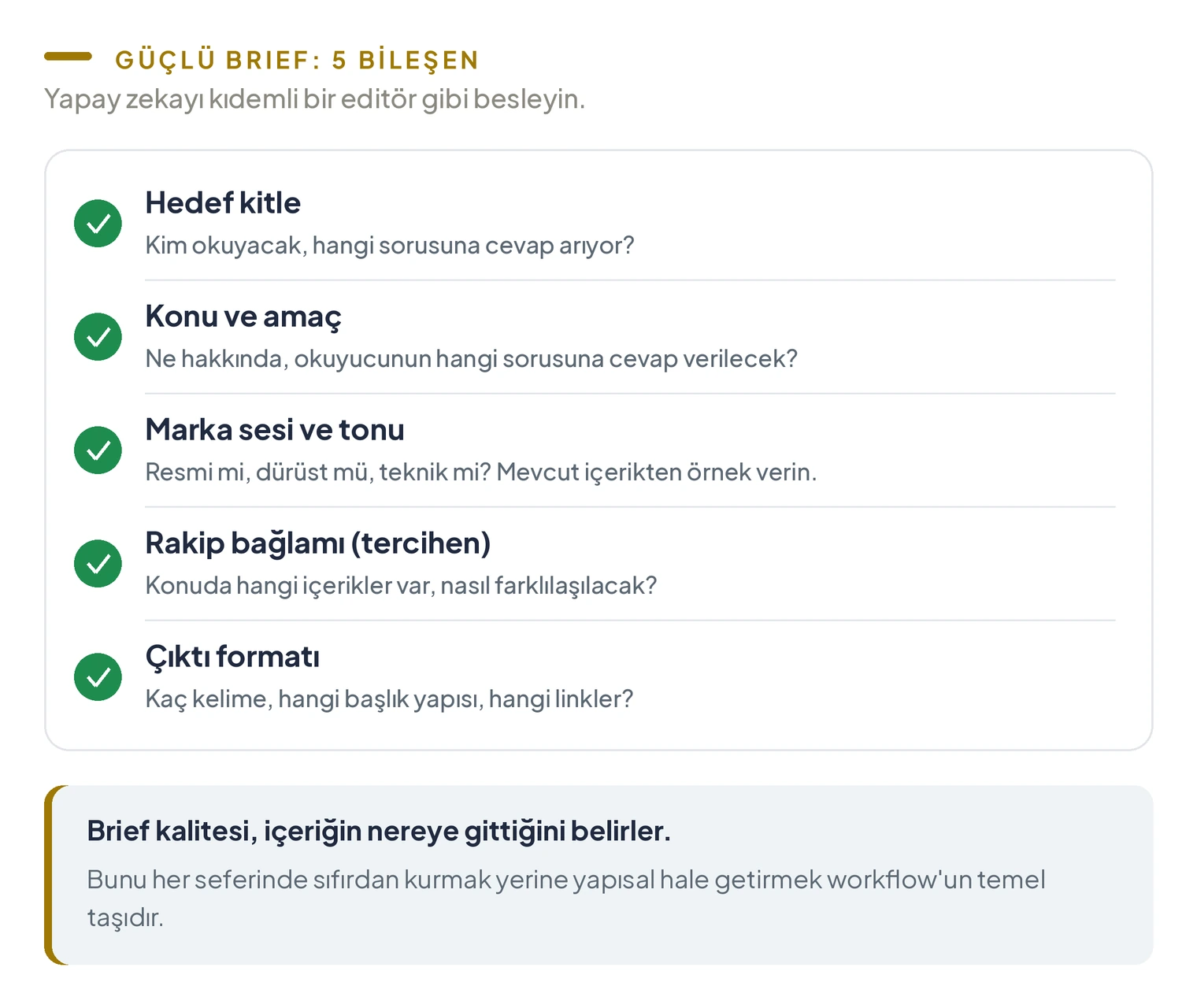
Yapay zekaya verilecek bir içerik brief’inde şu bileşenler bulunmalı:
- Hedef kitle: Bu içeriği kim okuyacak? Ne öğrenmek istiyor, hangi sorusuna cevap arıyor?
- Konu ve amaç: Ne hakkında yazılacak, okuyucunun hangi sorusuna cevap verilecek?
- Marka sesi ve tonu: Resmi mi, dürüst mü, teknik mi? Mevcut içeriklerden örnekler verin.
- Rakip bağlamı (tercihen): Konu için hangi içerikler zaten var, bunlardan nasıl farklılaşılacak?
- Çıktı formatı: Kaç kelime, hangi başlık yapısı, hangi linkler içermeli?
Google’ın içerikleri değerlendirdiği yardımcı içerik kılavuzu da tam bu hazırlığa işaret ediyor: deneyim, uzmanlık, otorite ve güven, içeriğin yapısından önce başlıyor.
Bu brief mantığı, içerik üretiminde workflow tasarımının temel taşı. Yapay zekayı bir sistem içinde kullanmak, brief’i her seferinde sıfırdan kurmak yerine yapısal hale getirmek anlamına geliyor.
Brief kalitesi, içeriğin nereye gittiğini belirliyor. Ama brief kadar önemli bir diğer karar da hangi modelle çalışacağınız.
Doğru yapay zeka modelini seçmek: içerik üretmenin yarısıdır
Aynı yapay zeka sağlayıcısının farklı modelleri arasında ciddi bir kapasite farkı var. Flash modeliyle Pro arasındaki fark, yalnızca hız değil; derinlik, bağlam tutma ve argüman kurma yetkinliğinde de belirgin.
Ayrıca yapay zeka modellerinin arasındaki farklar; içeriğin kalitesini etkilediği gibi briefe uygunluk ve tutarlılık oranını da etkiler. Siz ne kadar doğru bağlam, promtp veya brief verirseniz verin düşük model “hızlı cevap” üretimine odaklı çalışma modeli nedeniyle brief dışına çıkar. Eksik noktalar bırakır veya tamamen uydurma bilgi sunar.
Paylaştığım SEO uzmanı deneyimindeki ikinci sorun buradaydı. Gemini kullanıcısıydı ama hız ve maliyet gerekçesiyle Flash modelini seçmişti. Sonuç, kullandığı aracın değil, seçtiği modelin kapasitesini yansıtıyordu. OpenAI’nın model açıklamaları da her modelin hangi görevler için optimize edildiğini net biçimde ortaya koyuyor: uzun biçimli içerik üretimi ve derinlikli araştırma, üst segment modeller için tasarlanmış görevler.
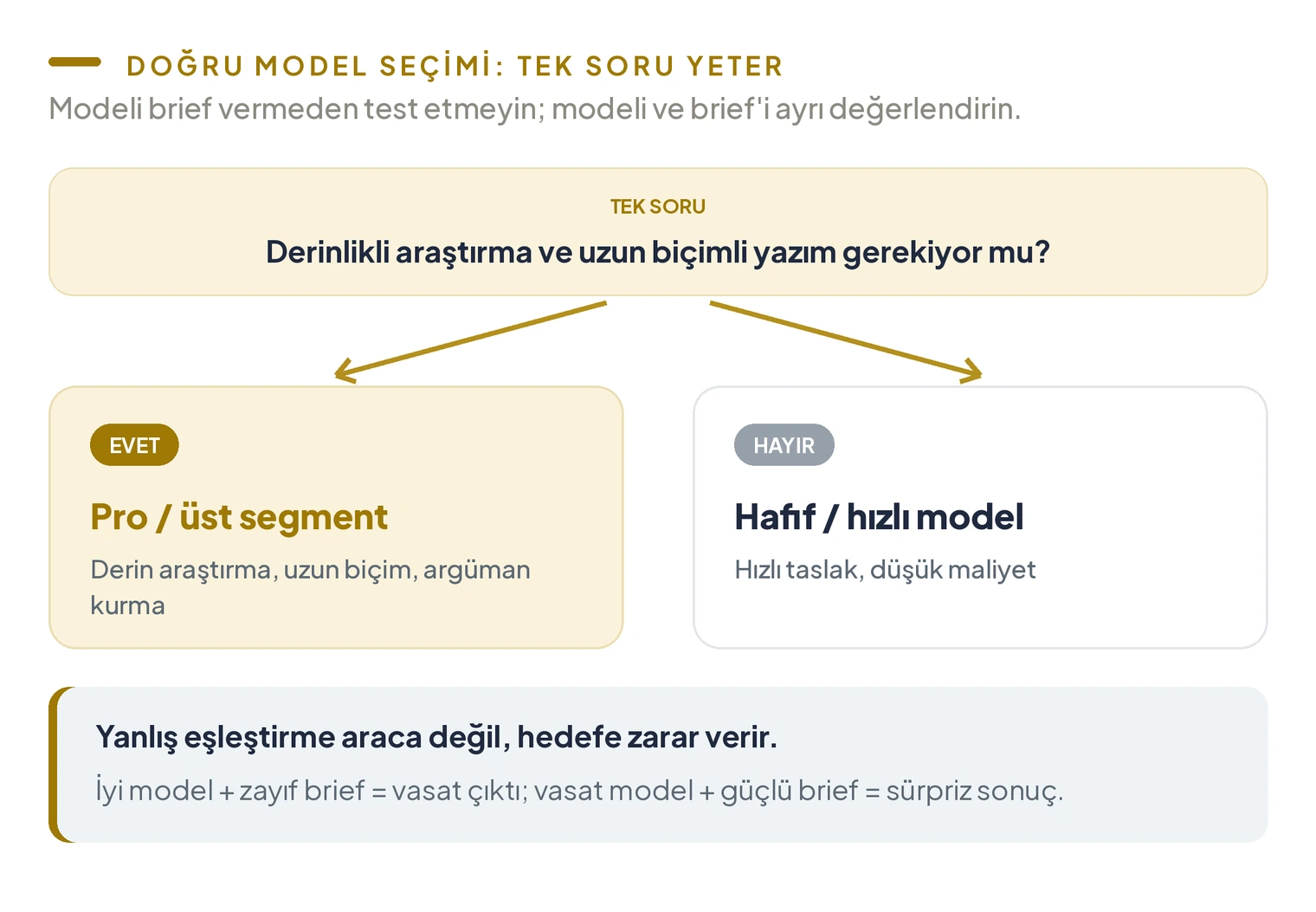
Yapay zeka modelini seçerken tek soru sormak yeterli: “Bu içerik için derinlikli araştırma ve uzun biçimli yazım mı gerekiyor, yoksa hızlı bir taslak mı?” Birincisi Pro veya üst segment model; ikincisi daha hafif bir seçenek. Yanlış eşleştirme, araca değil hedefe zarar veriyor.
Bir başka değerlendirme eksikliği de modeli brief vermeden test etmek. İyi bir model, zayıf bir brief’le vasat bir çıktı verir. Vasat bir model, güçlü bir brief’le sürpriz sonuçlar üretebilir. İkisini ayrı ayrı değerlendirmeden araç hakkında karar vermek, ölçümü yanlış yerde yapmak demek.
Doğru model ve güçlü brief bir araya geldiğinde asıl mesele karşılaştırmaya dönüşüyor: bir yazar bunu yapabilir mi?
Yapay zeka mı, yazar mı?
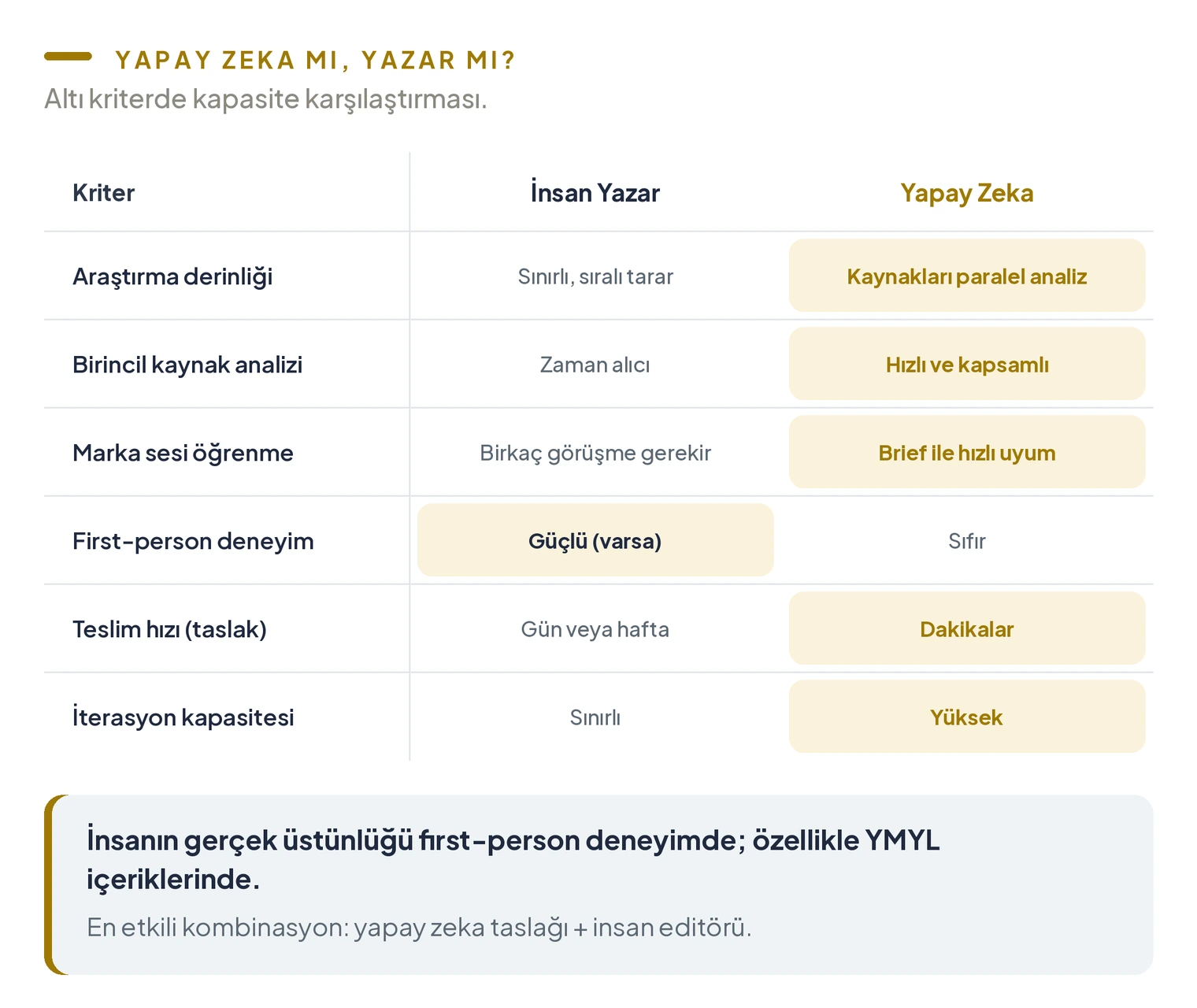
İçerik üretiminde yapay zekayı insan yazara tercih etmek için birkaç somut gerekçe var. Araştırma derinliği, birincil kaynak analizi ve marka sesi öğrenme hızında yapay zekanın üstünlüğü belirgin. Ama bu üstünlüğün bir sınırı var.
| Kriter | İnsan Yazar | Yapay Zeka |
|---|---|---|
| Araştırma derinliği | Sınırlı; kaynakları sıralı tarar | Onlarca kaynağı paralel analiz eder |
| Birincil kaynak analizi | Zaman alıcı | Hızlı ve kapsamlı |
| Marka sesi öğrenme | Birkaç görüşme gerekir | Brief ve örneklerle hızlı uyum |
| First-person deneyim | Güçlü (varsa) | Sıfır |
| Teslim hızı (taslak) | Gün veya hafta | Dakikalar |
| İterasyon kapasitesi | Sınırlı | Yüksek |
İnsan yazarın gerçek üstünlüğü first-person deneyimde. Eğer içeriğin kalitesi bizzat yaşanmış bir deneyimle destekleniyorsa, yazar bu alanda yapay zekayı geride bırakıyor. Bu fark, YMYL (Your Money or Your Life) içeriklerinde daha da belirgin: sağlık veya hukuk alanında uzmanın anlattığı ile bir yazarın aktardığı arasındaki güven farkı, içerik pazarlaması stratejisinin en hassas kısmını oluşturuyor.
Yapay zeka bu deneyim boşluğunu kapatamıyor. Ama araştırma, yapı kurma ve taslak oluşturma aşamalarında insan verimliliğini ciddi ölçüde artırıyor. En etkili kombinasyon, yapay zeka taslağı ve insan editörü birlikteliğinde ortaya çıkıyor.
Yapay zekayla insan yazarın üstünlük alanları netleşince, araç hakkındaki bazı yaygın yanlış inançları da ele almak gerekiyor.
Yapay zeka hakkında yerleşen iki yanılgı
Yapay zekayla içerik üretiminde en sık karşılaştığım iki yanlış inanç, süreçten önce zihinde düzeltilmesi gereken şeyler.
“Yapay zeka metin üretir” yanılgısı
Birden fazla şubesi olan bir hastanenin dijital pazarlama ekibiyle görüşme yapmıştım. Orada yapay zekayla ilgili bir inanç yerleşmişti: araç, herkese aynı metni ve aynı cevabı veriyor. Ekipteki bazı kişiler yapay zekayı, sanki herkese aynı telden çalan chat aracı olarak konumlandırmış gibiydi.
Bu inanç, yapay zekanın kuruma sağlayabileceği katkının önünde ciddi bir engel oluşturuyor. Çünkü yapay zeka bir metin üretici değil; araştırma yapan, analiz eden, strateji kuran ve verilen bağlama göre kalite sunan bir asistan. Nasıl beslenirse, nasıl yönlendirilirse ona göre şekilleniyor. Her kuruma, her markaya, her içerik hedefine farklı çıktı üretmesi bunun göstergesi.
“Herkese aynı cevabı veriyor” inanışı, yapay zekayı bir navigasyon uygulaması gibi kullanmaktan geliyor: soruyorsun, alıyorsun. Oysa yapay zekayla içerik üretimi, kıdemli bir danışmanla çalışmaya daha çok benziyor. Ne kadar beslerseniz, ne kadar bağlam verirseniz, çıktı o kadar markanıza özgü oluyor.
AI detector araçları güvenilir mi?
AI detector araçlarının içeriklerdeki yapay zeka izini tespit ettiği iddiası temelsiz. Kendi ürettiğim içerikleri, tamamen insan kalemi ürünü metinleri bu araçlardan geçirdim; sonuç “%90 gibi yüksek bir oranla GenAI üretimi” olarak çıktı. Aynı testi tamamen Claude ile ürettiğim içerikler için yaptım; bu sefer “%10 GenAI üretimi” sonucunu aldım.

Farklı modellerle üretilen içerikleri de test ettim. Sonuç her seferinde aynı tutarsız tabloyu ortaya koydu. Bu araçlar, metnin kimin yazdığını değil; bazı modellerin bıraktığı teknik izleri (belirli yazı kalıpları, noktalama tercihleri gibi) tarıyor. Bu izler kaldırıldığında araç tutarsız sonuçlar vermeye başlıyor.
Yapay zeka içeriklerini tespit etmeye çalışmak yerine, içeriğin kalitesini değerlendirmek çok daha anlamlı bir soru. Google, içerikleri otomasyon nedeniyle değil, kalitesiz oldukları için değerlendiriyor. Bağlam vererek, doğru modeli seçerek ve taslağı insan gözüyle geçirerek üretilen bir içerik, kıdemli bir editörün çıktısından ayırt edilemiyor. Hatta bazen çıktı kalitesi o kadar yüksek olur ki, bu iyi bir sonuçtur; sorun değil.
Yanılgılar bir yana bırakıldığında, asıl soru şuraya geliyor: yapay zekayı tek seferlik bir araç olarak mı yoksa sistematik bir süreç olarak mı kullanacaksınız?
Araçtan sisteme: yapay zeka içerik workflow’u
Yapay zekayla bir kez içerik üretmek ile sistematik bir içerik üretim süreci kurmak arasındaki fark, ölçek ve tutarlılıkta somutlaşıyor. Aynı kalite çıktıyı tekrar tekrar, farklı konularda ve farklı kişiler aracılığıyla elde etmek için bir workflow gerekiyor.
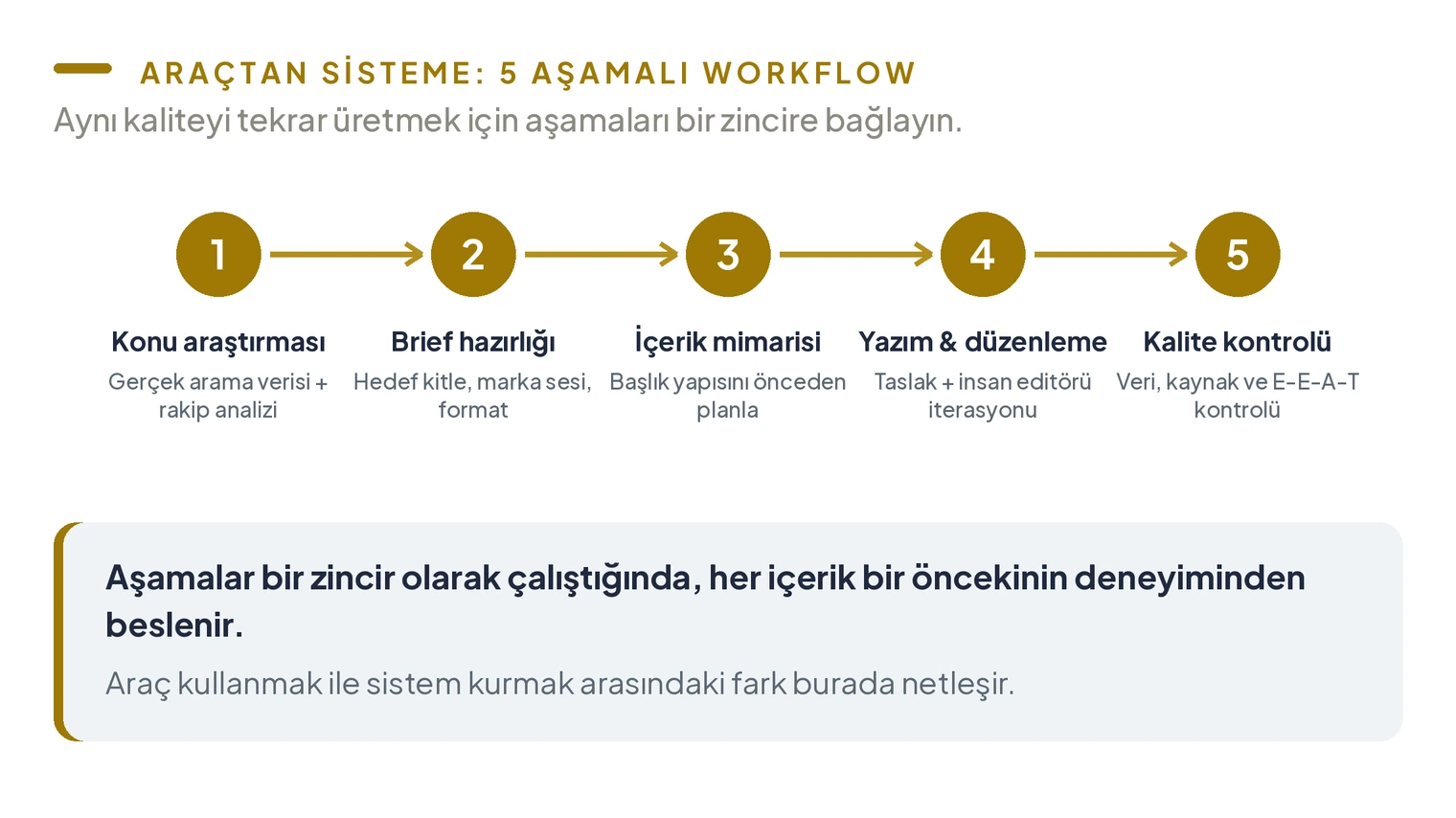
Benim yapay zeka içerik üretim sistemimde beş aşama var:
- Konu araştırması ve niyet analizi: Hedef kelime için gerçek arama verisini ve rakip içerikleri inceleyin. Ne arıyorlar, rakipler neyi eksik bırakmış?
- Brief ve bağlam hazırlığı: Hedef kitle, marka sesi, içerik amacı ve format belirleyin. Bu adım atlandığında çıktı kalitesi doğrudan düşüyor.
- İçerik mimarisi: Başlık yapısını ve hangi bilginin nerede yer alacağını önceden planlayın. Yapay zeka planlanmış bir yapıya çok daha uygun içerik üretiyor.
- Yazım ve düzenleme: Yapay zeka taslağı üretir, insan editörü rafine eder. Bu döngüde birden fazla iterasyon normaldir.
- Kalite kontrolü: Gerçek veri, birincil kaynaklar ve E-E-A-T sinyalleri metne doğru yerlerde yerleştirildi mi kontrol edin.
Araç kullanmak ile sistem kurmak arasındaki fark burada netleşiyor. Yapay zeka içerik üretim masası bu aşamaların tek tek uygulama yerine bir zincir olarak çalıştığı yapıyı tanımlıyor. Zincir kurulduğunda, her içerik üretimi bir öncekinin deneyiminden besleniyor.
Workflow tutarlılığı sağladıkça içeriğin bir başka boyutu gündeme geliyor: bu içerikler nerede değerlendiriliyor ve hangi kurallara göre okunuyor?
GEO’ya uygun içerik neden farklı üretilmeli?
Yapay zeka arama motorları (ChatGPT, Gemini, Perplexity), bir konuda kaynak gösterecekleri içerikleri geleneksel arama motorlarından farklı kriterlerle değerlendiriyor. Bu farkı görmezden gelen bir içerik stratejisi, doğru üretilmiş içerikleri bile görünmez kılabiliyor.

BrightEdge’in araştırması, sağlık sorgularının yaklaşık yüzde sekseninin yapay zeka motorlarının cevaplarıyla karşılandığını ortaya koyuyor. SparkToro’nun analizi ise Google aramalarının yarısından fazlasının tıklamaya gerek kalmadan sonuçlandığını gösteriyor. Bu iki veri bir arada okunduğunda tablo netleşiyor: sıralama artık tek başına yeterli değil.
GEO (Generative Engine Optimization), içeriği yapay zeka motorlarının kaynak havuzuna girecek şekilde üretmeyi hedefliyor. Bunun için birkaç yapısal özellik gerekiyor: cevabı metnin başına koyan açılış, kısa ve doğrudan bilgi blokları, gerçek veriye dayalı uzmanlık sinyalleri ve yapısal veri (schema) kullanımı.
Yapay zekayla üretilen içerik, baştan bu yapıya göre kurgulanırsa iki hedefe aynı anda hizmet ediyor: geleneksel arama motorlarında sıralama ve yapay zeka motorlarında kaynak görünürlüğü. İkisini ayrı ayrı hedeflemek yerine, içerik mimarisini baştan bu ikiliğe göre planlamak çok daha verimli.
Bu dönüşümü stratejik bir süreç olarak yürütmek istiyorsanız SEO stratejisi üzerine çalışabiliriz.
Başarı başlangıçta biter
Yapay zeka ile içerik üretiminde sonucu belirleyen üç şey: brief, model ve sistem. Üçü bir arada yoksa çıktı kalitesi rastlantıya kalıyor.
Brief, modele ne üretmesi gerektiğini söylüyor. Model, bu talimatı işleyecek kapasiteyi sunuyor. Sistem ise bu süreçlerin tutarlı ve tekrarlanabilir şekilde işlemesini sağlıyor. Birini atladığınızda diğer ikisi de zayıflıyor.
Yapay zeka içerik üretiminin gerçek değeri, bir kez deneyip bırakılan bir özellikte değil; iyi kurulmuş bir süreçte gizli. Bu süreç kurulduğunda içerik ekiplerinin zamanı araştırma ve üretimden editöryal kararlara kayıyor; bu da marka sesinin ve içerik kalitesinin zamanla güçlenmesi anlamına geliyor.
