Doktorun ismi, uzmanlığı ve içerik yazarı sayfada doğru görünebilir. Buna rağmen tema bir Person, SEO eklentisi başka bir Organization, özel kod ise farklı bir kimlik taşıyan Physician üretebilir. Ziyaretçinin görmediği bu çelişki, aynı gerçek kişi ve kurumu makineler için üç ayrı entity gibi tanımlayabilir.
Yapısal veri, görünür içeriğin yerine geçen bir SEO katmanı değildir. Sayfadaki gerçekleri standart bir sözlükle sınıflandırır ve entityler arasındaki ilişkileri makinece okunabilir hale getirir. Doktorlar için schema çalışmasının değeri de kod miktarından değil, görünür içerik, kalıcı kimlikler, sayfa amacı ve güncelleme süreci arasındaki tutarlılıktan gelir.
Doktor web sitesinde schema kullanmak zorunlu mu?
Schema kullanımı bir doktor sitesinin Google tarafından indekslenmesi için teknik bir şart değildir. Yapılandırılmış verisi bulunmayan bir sayfa da taranabilir, indekslenebilir ve arama sonuçlarında gösterilebilir. Schema ayrıca içerik kalitesini yükseltmez, hatalı canonical yapısını düzeltmez ve arama motorunun erişemediği sayfayı erişilebilir hale getirmez.
Buna karşılık doğru uygulanan schema, sayfanın ana konusunu, yazarı, yayıncısı, breadcrumb yapısı ve ilgili entityleri hakkında açık ipuçları verir. Desteklenen bir arama özelliğinde rich result uygunluğu sağlayabilir. Uygunluk görünüm garantisi değildir. Google, işaretleme teknik testten geçse bile ilgili özelliği göstermeyebilir.
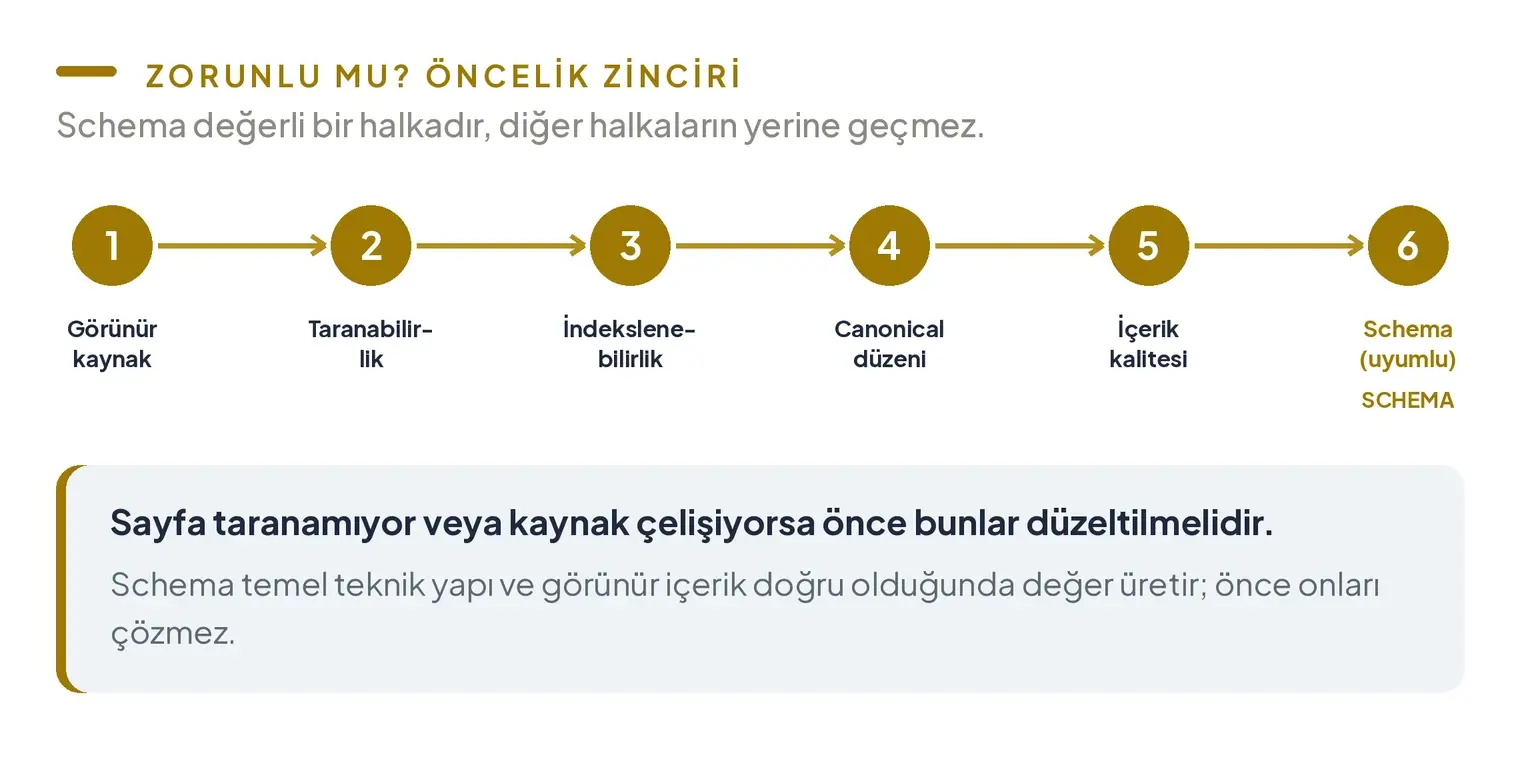
Bu nedenle “zorunlu mu?” sorusuna verilecek pratik cevap, sitenin mevcut durumuna bağlıdır:
- Sayfa taranamıyor, yanlış canonical taşıyor veya görünür içerik yetersizse önce bu sorunlar düzeltilmelidir.
- Doktorun ismi, uzmanlığı, profil bilgileri ve kurum ilişkileri sayfalar arasında çelişiyorsa önce kaynak gerçek netleştirilmelidir.
- Temel teknik yapı ve görünür içerik doğruysa schema, bu gerçeği makineler için açıklaştıran önerilen bir uygulamadır.
- Desteklenen rich result türleri hedefleniyorsa ilgili Google özelliğinin gerekli ve önerilen alanları ayrıca karşılanmalıdır.
Öncelik sırası görünür kaynak gerçek, taranabilirlik, indekslenebilirlik, canonical düzeni, içerik kalitesi ve bunlarla eşleşen schema şeklinde kurulabilir. Schema bu zincirin değerli bir parçasıdır, fakat diğer halkaların yerine geçmez.
Bu teknik katmanın site mimarisi, içerik ve güven sinyalleriyle ilişkisini doktorlar için SEO pillar sayfasında ele alıyorum.
Yapay zeka aramalarında schema neden önemli?
Yapay zeka destekli arama özellikleri bir sayfayı yalnızca JSON-LD koduna bakarak seçmez. İçeriğin indekslenebilir olması, sorguyu karşılaması, metinsel olarak erişilebilir kalması ve güvenilir bir kaynak sunması gerekir. Schema, bu temelin üzerinde isim, tür, yazar, yayıncı ve sayfa ilişkilerini daha açık hale getiren yardımcı bir veri katmanıdır.
Google’ın AI özellikleri için site sahiplerine sunduğu rehber, AI Overviews veya AI Mode için ek teknik şart ya da özel schema gerekmediğini belirtiyor. Aynı belgede mevcut yapılandırılmış verinin görünür metinle eşleşmesi, önemli içeriğin metin biçiminde bulunması ve temel SEO uygulamalarının korunması öneriliyor.
Buradaki değer “AI için yeni bir schema” üretmek değildir. Doktor profilindeki isim ile global Person entitysinin, içerikteki yazar ile BlogPosting.author referansının ve hizmet sayfasındaki görünür kapsam ile sayfa graphının çelişmemesidir. Bu tutarlılık makinelerin yorum yükünü azaltabilir. Bir sayfanın seçileceğini veya kaynak gösterileceğini tek başına belirlemez.
Özel AI dosyaları, görünmez metinler veya her sayfaya eklenen geniş entity listeleri yerine güncel kaynak gerçek, net içerik, erişilebilir HTML, doğrulanmış iç linkler ve sayfa amacıyla uyumlu schema birlikte yönetilmelidir.
Schema ile yapay zeka görünürlüğü arasındaki daha geniş ilişkiyi doktorlar için GEO pillar içeriğinde ayrıntılandırıyorum.
Doktor sitesi için hangi schema türleri kullanılmalı?
Tür seçimi “sağlık sitesi” etiketiyle topluca yapılamaz. Önce sayfanın ana amacı ve anlattığı temel entity belirlenir. Bir doktorun profil sayfası, bir kliniğin lokasyon sayfası, tıbbi bilgi içeriği ve blog yazısı farklı görevler taşır. Aynı schema paketini bu sayfaların tamamına kopyalamak, ayrıntı eklemek yerine graphı belirsizleştirebilir.
Sayfa amacına göre tür seçimi

Aşağıdaki matris, Schema.org sözlüğündeki türleri sayfa amacıyla eşler. Bir türün Schema.org içinde bulunması, Google’ın o tür için ayrı bir rich result gösterdiği anlamına gelmez. Google Search davranışı için ilgili Search Central özelliği ayrıca kontrol edilmelidir.
| Sayfa veya kapsam | Ana entity | Değerlendirilebilecek tür | Dikkat noktası |
|---|---|---|---|
| Site geneli | Website ve yayıncı kurum | WebSite, Organization | Tek kalıcı kimlik kullanılır; her sayfada tam tanım tekrarlanmaz. |
| Bireysel doktor profili | Gerçek kişi ve mesleki profil | Person, duruma göre Physician, ProfilePage | Kişi ile doktor ofisi aynı node gibi ele alınmamalı; görünür profil ve tüketici desteği kontrol edilmelidir. |
| Klinik veya lokasyon sayfası | Fiziksel sağlık kuruluşu | MedicalClinic veya uygun kuruluş alt türü | Adres, telefon, çalışma saatleri ve uzmanlık görünür kaynakla aynı olmalıdır. |
| Tıbbi bilgi sayfası | Belirli bir tıbbi konu | MedicalWebPage ve yalnızca içerikle uyumlu ilgili türler | Her içerik için otomatik seçim yapılmaz; konu, yazar ve inceleme süreci görünür olmalıdır. |
| Blog yazısı | Yayınlanmış içerik | BlogPosting, WebPage, BreadcrumbList | Yazar ve yayıncı global entity kimliklerine referans vermelidir. |
| Hizmet sayfası | Sunulan hizmet ve açıklayıcı içerik | Service, WebPage, duruma göre Article | Sunulmayan hizmet, fiyat veya özellik yalnızca schema içinde beyan edilmemelidir. |
Bir sayfada birden fazla tür bulunabilir, fakat her türün ayrı bir görevi olmalıdır. WebPage sayfanın kendisini, BlogPosting yayınlanan içeriği, Person yazarı ve Organization yayıncıyı temsil edebilir. Bunları tek bir node içinde rastgele birleştirmek yerine aralarındaki ilişkiyi mainEntityOfPage, author, publisher ve kalıcı kimlik referanslarıyla kurmak graphı daha okunabilir tutar.
Person ile Physician seçimi özellikle dikkat ister. Schema.org hiyerarşisinde Physician, hem bir doktoru hem de doktor ofisini temsil edebilen tıbbi kuruluş ve yerel işletme çizgisinde tanımlanır. Bir sitenin gerçek kişi kimliğini global Person olarak koruyup profil veya ofis bağlamını ayrı bir node ile modellemesi mümkündür. Başka bir yapıda uyumlu çoklu tür kullanılabilir. Karar, kopyalanan bir şablona değil, entitynin ne olduğuna ve veriyi tüketen sistemin neyi desteklediğine dayanmalıdır.
MedicalWebPage de “doktor sitesindeki bütün içerikler” anlamına gelmez. Schema.org bu türü tıbbi bilgi sunan web sayfası olarak tanımlar. Bir ajans duyurusu, kurum haberi veya genel SEO yazısı doktor sitesinde yayımlansa bile tıbbi bilgi sayfası olmayabilir. Buna karşılık belirli bir tıbbi konuyu açıklayan sayfada ana konu, hedef kitle, inceleme ve güncellik ilişkileri gerçekten mevcutsa bu tür değerlendirilebilir.
Schema.org Physician türü, bireysel doktoru veya MedicalOrganization kabul edilen doktor ofisini tanımlar; medicalSpecialty ve hospitalAffiliation gibi özellikler içerir. Bu tanım, gerçek kişi kimliğinin sitede nasıl modelleneceğine tek başına karar vermez. Profil yapısı, kurum ilişkisi, görünür bilgi ve hedef platform desteği birlikte değerlendirilmelidir.
Entity graph içinde @id, url ve sameAs nasıl ayrılır?
@id, graph içindeki entity için kalıcı referans kimliğidir. Örneğin doktorun bütün site boyunca kullanılan kişi node’u https://ornek.com/#person kimliğini taşıyabilir. Blog yazısındaki author alanı aynı kişiyi yeniden ayrıntılarıyla yazmak yerine bu kimliğe referans verir.
url, entity hakkında ziyaret edilebilir resmi sayfayı gösterir. Doktor entitysi için bu değer profil sayfası olabilir. sameAs ise yalnızca aynı kişi veya kurumu açık biçimde tanımlayan dış profiller için kullanılır. Konuyla ilgili her yayın, dizin veya sosyal bağlantı sameAs değildir.
Sağlıklı bir graph üç kurala dayanır:
- Aynı entity site genelinde aynı
@iddeğerini korur. - Sayfaya özgü node’lar global kişi ve kurum node’larını yeniden tanımlamak yerine referans verir.
- Schema ilişkileri, menüde, profil sayfasında, yazar alanında ve içerikte görülen gerçekle çelişmez.
Bu yaklaşım entity optimizasyonu çalışmasının teknik bölümüdür. Amaç daha fazla entity eklemek değil, hangi ismin hangi gerçek kişi, kurum, sayfa ve konuya karşılık geldiğini belirsiz bırakmamaktır.
Schema, entity SEO ve E-E-A-T nasıl ilişkilidir?
Entity SEO, sitedeki kişi, kurum, hizmet, lokasyon ve konuların tutarlı kimliklerle birbirine bağlanmasını ele alır. E-E-A-T ise deneyim, uzmanlık, yetkinlik ve güvenilirliğin içerik ve site düzeyindeki görünür kanıtlarıyla değerlendirilir. Schema bu kanıtları oluşturmaz; mevcut gerçeğin belirli parçalarını yapılandırılmış biçimde temsil eder.
Doktorun profil sayfası uzmanlık bilgisini, eğitim ve kurum ilişkilerini görünür biçimde açıklıyorsa schema bu bilgileri uygun alanlarla eşleyebilir. İçerik uzman incelemesinden geçtiyse inceleyen kişi, inceleme tarihi ve profil bağlantısı görünür içerikte yer alabilir; graph da aynı ilişkiyi gösterebilir. Böyle bir süreç hiç yaşanmadıysa yalnızca reviewedBy eklemek uzman incelemesi üretmez.
Google, sağlığı önemli ölçüde etkileyebilecek konularda güçlü E-E-A-T ile uyumlu içeriğe daha fazla ağırlık verilebileceğini, E-E-A-T’nin ise tek başına belirli bir sıralama faktörü olmadığını açıklıyor. Doktor sitesinde uygulanabilir E-E-A-T değerlendirmesi, schema kontrolünden önce görünür yazar, kaynak, profil, güncellik ve inceleme sürecini sorgulamalıdır.
Schema E-E-A-T’yi temsil eder, kendi başına kanıtlamaz
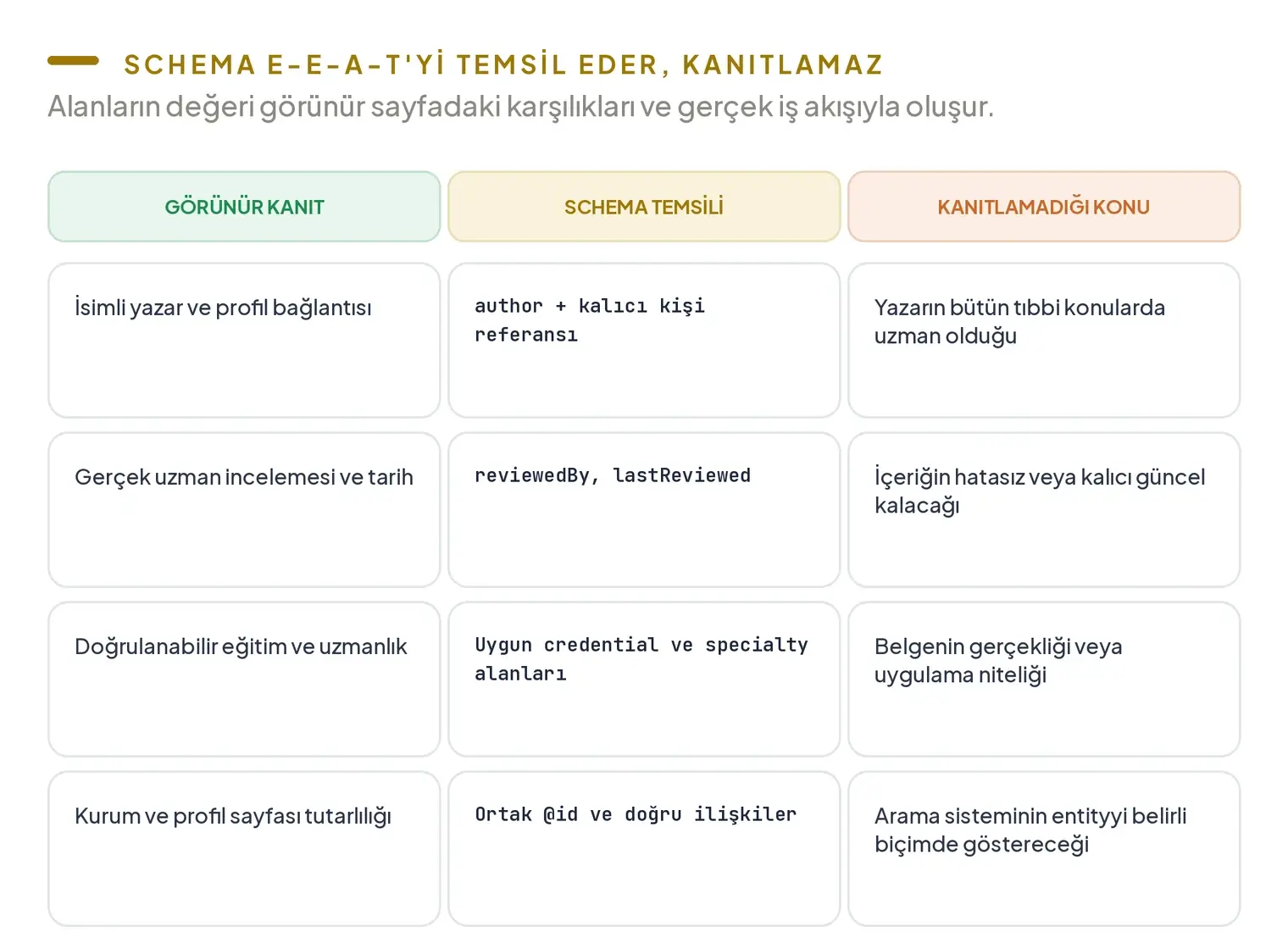
author, içeriğin yazarını; reviewedBy, doğruluk veya bütünlük açısından inceleme yapan kişi ya da kurumu; lastReviewed ise son inceleme tarihini temsil edebilir. Bu alanların değeri, görünür sayfadaki karşılıkları ve gerçek iş akışıyla oluşur.
| Görünür kanıt | Schema temsili | Tek başına kanıtlamadığı konu |
|---|---|---|
| İsimli yazar ve profil bağlantısı | author ve kalıcı kişi referansı | Yazarın bütün tıbbi konularda uzman olduğu |
| Gerçek uzman incelemesi ve tarih | reviewedBy, lastReviewed | İçeriğin hatasız olduğu veya kalıcı biçimde güncel kalacağı |
| Doğrulanabilir eğitim ve uzmanlık bilgisi | Uygun credential ve specialty alanları | Belgenin gerçekliği veya kişinin uygulama niteliği |
| Kurum ve profil sayfaları arasındaki tutarlılık | Ortak @id ve doğru ilişkiler | Arama sisteminin entityyi belirli bir biçimde göstereceği |
Schema denetimi bu yüzden yalnızca alanların dolu olup olmadığını kontrol etmemelidir. Her alan için “Bu bilgi sayfada görünüyor mu, kaynağı var mı, güncel mi ve bu node gerçekten aynı entityyi mi temsil ediyor?” soruları sorulmalıdır.
Schema yapay zeka atfı almaya etki eder mi?
Schema eklemenin bir içeriğe yapay zeka atfı kazandırdığını gösteren genel ve doğrudan bir nedensellik kanıtı yoktur. Google’ın resmi rehberi de AI Overviews ve AI Mode için özel schema gerekmediğini belirtir. Bu nedenle “schema ekledik, atıf alacağız” biçimindeki beklenti ölçülebilir bir strateji değildir.
Yapılandırılmış veri yine de dolaylı bir rol oynayabilir. Sayfanın yazarı, yayıncısı, ana konusu ve bağlı entityleri görünür içerikle aynı biçimde tanımlandığında makinece yorumlanabilirlik artabilir. Fakat atıf seçimi; sorgu uyumu, indekslenebilirlik, içerik derinliği, kaynak değeri, güncellik, dış doğrulamalar ve ilgili sistemin kullandığı model veya veri kaynaklarıyla birlikte oluşur.
Bu ilişkiyi değerlendirmek için schema kurulumunu tek başına başarı metriği yapmak yerine şu kayıtlar tutulabilir:
- Değiştirilen URL, schema node’ları, uygulama tarihi ve önceki sürüm.
- Takip edilen gerçek kullanıcı sorguları, platform ve kontrol tarihi.
- Atıf veya kaynak görünümü, kullanılan URL ve cevabın bağlamı.
- Aynı dönemde yapılan içerik, teknik SEO, iç link ve dış kaynak değişiklikleri.
GEO citation rate ölçümü, bu kayıtları sorgu ve zaman temelinde karşılaştırmaya yardımcı olur. Yine de ölçüm, schema ile atıf arasındaki ilişkiyi gözlemleyebilir; diğer değişkenler ayrılmadan doğrudan neden ilan edemez.
Doğrudan etkiyi neden kanıtlayamayız?
Bir sayfaya schema eklendikten sonra atıf alınması, tek başına schema’nın sonucu göstermez. Aynı dönemde içerik yeniden taranmış, iç link kazanmış, dış bir kaynakta anılmış veya platformun modeli değişmiş olabilir. Önce-sonra karşılaştırması bu değişkenleri ayırmıyorsa yalnızca zaman ilişkisi gösterir.
Platformların davranışı da aynı kabul edilemez. Google Search içindeki AI özelliklerinin teknik uygunluk şartları ile bağımsız bir cevap motorunun kaynak seçimi farklı olabilir. Bu nedenle ölçüm platform, sorgu, tarih ve kullanılan kaynak URL düzeyinde tutulmalı; sonuçlar bütün yapay zeka sistemlerine genellenmemelidir.
Doktor schema uygulamalarında en çok yapılan hatalar

Schema hatası yalnızca eksik virgül veya geçersiz JSON değildir. Teknik olarak ayrıştırılan bir graph da yanlış entityyi, eski bilgiyi veya görünür sayfayla çelişen bir ilişkiyi taşıyabilir. Bu nedenle sözdizimi, sayfa gerçeği ve graph bütünlüğü ayrı kontrollerdir.
| Hata | Olası etki | Kontrol | Düzeltme |
|---|---|---|---|
| Görünmeyen bilgiyi işaretlemek | İşaretleme yanıltıcı sayılabilir veya rich result uygunluğu kaybedilebilir. | Her schema alanını görünür sayfadaki karşılığıyla eşleyin. | Bilgiyi kullanıcı için görünür yapın veya graph içinden çıkarın. |
| Yanlış ana tür seçmek | Kişi, ofis, klinik ve içerik ilişkileri belirsizleşir. | Sayfanın ana amacı ile node türünü karşılaştırın. | Önce entity ve sayfa rolünü belirleyip en uygun türü kullanın. |
| Global entityleri her sayfada yeniden tanımlamak | Farklı bilgi veya kimlik taşıyan kopya node’lar oluşabilir. | @id envanterini ve tüm JSON-LD bloklarını tarayın. | Tek canonical entity tanımı kurup sayfa graphlarından referans verin. |
| Uydurulmuş veya eski uzmanlık bilgisi | Görünür profil, dış kaynaklar ve schema arasında güven sorunu oluşur. | Uzmanlık, kurum ilişkisi ve belge kaynaklarını doğrulayın. | Kaynağı olmayan alanı kaldırın; değişiklik sahibini belirleyin. |
| Kendi kontrolündeki yorumları yıldız görünümü için işaretlemek | Google’ın self-serving review kuralları nedeniyle özellik uygunluğu oluşmayabilir. | İncelenen entity, yayıncı ve yorum kaynağı ilişkisini kontrol edin. | Review işaretlemesini görünür içerik ve ilgili özellik yönergesiyle sınırlandırın. |
| Görünür SSS olmadan SSS schema eklemek | Schema görünür ana içerikle eşleşmez. | Her soru ve cevabın sayfada kullanıcı tarafından okunabildiğini doğrulayın. | Görünür bölüm yoksa işaretlemeyi kaldırın; görünüm beklentisini uygunluktan ayırın. |
| Canonical URL ile schema kimliğini ayırmak | Aynı sayfa için farklı graph kimlikleri oluşur. | url, @id, breadcrumb ve canonical değerlerini karşılaştırın. | Kimlikleri tek canonical URL sözleşmesinden üretin. |
| Test aracından geçen kodu görünüm garantisi sanmak | Teknik geçerlilik ile arama özelliği uygunluğu karıştırılır. | Schema.org geçerliliği, Google özelliği ve canlı URL kontrolünü ayırın. | Her testin neyi doğruladığını raporda açıkça yazın. |
Google’ın genel yapılandırılmış veri yönergeleri, görünür olmayan veya yanıltıcı içeriğin işaretlenmemesini ister. Bir yapılandırılmış veri manuel işlemi rich result uygunluğunu etkileyebilir; bu durum web aramasındaki sıralamaya verilen ayrı bir ceza gibi açıklanmamalıdır. Aynı şekilde tanınmış ve otoriter kamu veya sağlık siteleri için sınırlı bir SSS görünüm imkanı bulunması, her doktor sitesinin bu görünümü alacağı anlamına gelmez.
WordPress’te çift schema sorunu nasıl oluşur?
WordPress’te tema, SEO eklentisi, yorum eklentisi ve özel kod aynı sayfada ayrı JSON-LD blokları üretebilir. Birden fazla blok bulunması kendi başına hata değildir. Sorun, aynı WebPage, Person veya Organization entitysinin farklı @id, isim, URL ya da ilişkiyle tekrar tanımlanmasıdır.
Kontrol şu sırayla yapılabilir:
- Sayfanın kaynak kodundaki bütün
application/ld+jsonbloklarını listeleyin. - Render edilmiş DOM içinde JavaScript ile sonradan eklenen blokları ayrıca kontrol edin.
- Her node için tür,
@id,urlve bağlı entity referanslarını karşılaştırın. - Global entityleri hangi katmanın, sayfa graphını hangi katmanın üreteceğini belirleyin.
- Gereksiz üretimi tema veya eklenti ayarından kapatın; özel kodu tek sözleşmeye bağlayın.
Tek sahiplik, bütün schema’nın tek script içinde bulunması demek değildir. Global ve sayfaya özgü graph ayrı yerlerde yönetilebilir. Her node için tek bir kaynak gerçek ve çelişmeyen kalıcı kimlik bulunması gerekir.
Schema yönetim sistemi nasıl kurulur?

Sürdürülebilir schema yönetimi, generator üzerinden kod üretip siteye yapıştırmakla tamamlanmaz. Doktorun uzmanlığı, kurum ilişkisi, içerik yazarı, lokasyon veya çalışma saatleri değiştiğinde graph da güncellenmelidir. Bunun için veri kaynağı, teknik sahip, test ve geri alma süreci birlikte tanımlanır.
- Entity envanterini çıkarın. Doktor, kurum, website, logo, lokasyon, hizmet ve içerik türlerini; görünür kaynak sayfalarıyla birlikte kaydedin.
- Canonical kimlik sözlüğü kurun. Global entityler ve sayfaya özgü node’lar için kullanılacak
@idkurallarını belirleyin. - Sayfa türü sözleşmesi yazın. Blog, profil, hizmet, lokasyon ve vaka sayfalarında hangi node’ların kim tarafından üretileceğini ayırın.
- Görünür içerik eşlemesi yapın. Her schema alanının sayfada görülen karşılığını, veri sahibini ve güncelleme kaynağını kaydedin.
- Geliştirme kontrollerini ayırın. JSON sözdizimi, Schema.org sözlüğü, Google özelliği uygunluğu, HTML eşleşmesi ve entity bütünlüğünü farklı kapılarda doğrulayın.
- Kontrollü yayın uygulayın. Ön izleme, sürüm kaydı, değişiklik özeti ve geri alma imkanı olmadan canlı graphı topluca değiştirmeyin.
- Canlı URL’yi izleyin. URL Inspection, Search Console raporları, kaynak kodu ve render edilmiş DOM üzerinden üretimin beklenen biçimde kaldığını kontrol edin.
Entity envanteri yalnızca tür listesinden oluşmamalıdır. Her kayıt için canonical kimlik, görünür kaynak sayfa, teknik üretim katmanı, verinin iş sahibi, son doğrulama tarihi ve değişiklik tetikleyicisi tutulabilir. Örneğin doktorun unvanı profil ekibi tarafından, çalışma saati lokasyon sorumlusu tarafından, sayfa graphı ise teknik ekip tarafından yönetiliyorsa bu sorumluluklar aynı kayıtta buluşur. Böylece hangi bilginin kim tarafından doğrulanacağı belirsiz kalmaz.
Sayfa türü sözleşmesi de yalnızca zorunlu node listesini içermemelidir. Hangi global entitylerin dışarıdan referans verileceği, breadcrumb derinliği, canonical kimlik kalıbı, görünür yazar alanı, tarih biçimi, görsel gereksinimi ve schema’nın içerikten önce mi sonra mı üretileceği tanımlanabilir. Blog ile vaka aynı BlogPosting temelini kullansa bile görünür içerik sözleşmeleri farklı olabilir. Vaka sayfasında başlangıç durumu, uygulama, kanıt, sonuç ve sınırlama görünürken standart blogda bu anlatı zorunlu değildir.
Yayın sürecinde en az üç kontrol noktası yararlıdır. İçerik kontrolü görünür iddiaları ve kaynakları, yapı kontrolü HTML ve erişilebilirliği, schema kontrolü ise graph ilişkileri ile canonical entityleri denetler. Bu kapıları tek “test geçti” işaretine birleştirmek, teknik olarak geçerli fakat içerikle çelişen bir graphın yayına çıkmasına izin verebilir.
Rich Results Test, Google’ın desteklediği özellikler için uygunluk ve bazı teknik hataları kontrol eder. Schema Markup Validator daha geniş Schema.org sözlüğünü doğrular. URL Inspection ise Google’ın canlı veya indekslenmiş sayfada ne gördüğünü değerlendirmeye yardımcı olur. Bu araçlardan birinin geçmesi diğer kontrollerin tamamlandığını göstermez.
Yönetim raporu en az node sahibi, kaynak URL, son doğrulama tarihi, değişiklik nedeni, kullanılan testler ve geri alma sürümünü içermelidir. Böylece schema sessizce eskiyen bir kod bloğu olmaktan çıkar ve değişiklikleri izlenebilen bir site bileşeni haline gelir.
Hangi değişikliklerden sonra schema yeniden test edilmeli?
Schema yalnızca ilk kurulumda değil, onu üreten veya temsil ettiği gerçeği değiştiren olaylardan sonra yeniden denetlenmelidir:
- Tema, SEO eklentisi, page builder veya özel schema kodu güncellendiğinde
- Doktorun kullanılan ismi, unvanı, uzmanlığı, profil URL’si veya kurum ilişkisi değiştiğinde
- Adres, telefon, çalışma saati, lokasyon veya hizmet kapsamı güncellendiğinde
- İçeriğin yazarı, inceleyen kişisi, yayın veya inceleme tarihi değiştiğinde
- Slug, canonical, breadcrumb veya site mimarisi değiştiğinde
- Yeni sayfa şablonu ya da yeni içerik türü devreye alındığında
- Google belirli bir yapılandırılmış veri özelliğinin desteğini veya yönergesini değiştirdiğinde
Otomatik testler sözdizimi ve sözleşme hatalarını erken yakalayabilir. Entitynin gerçek dünyadaki karşılığını, bir bilginin hâlâ güncel olup olmadığını ve görünür içeriğin kullanıcıya yeterli açıklama sunup sunmadığını insan kontrolü tamamlamalıdır.
Sonuç: Schema’yı kod parçası değil, veri sözleşmesi olarak yönetin
Doktorlar için schema indeksleme şartı veya doğrudan sıralama faktörü değildir. Doğru yerde kullanıldığında görünür içeriğin ana entitylerini, yazar ve yayıncı ilişkilerini, sayfa türünü ve site hiyerarşisini daha açık biçimde temsil eder. Yapay zeka aramalarında da özel bir geçiş bileti değil, temel SEO ve içerik kalitesiyle uyumlu yardımcı bir katmandır.
Uygulama sırası kaynak gerçeği doğrulama, entity envanteri, canonical kimlikler, sayfa türü sözleşmesi, görünür içerikle eşleşen JSON-LD, kontrollü yayın ve düzenli izleme şeklinde kurulmalıdır. Bu sıra, daha fazla schema türü eklemekten önce mevcut graphın doğru, tutarlı ve güncel kalmasını sağlar.
Başarı, eklenen özellik sayısıyla değil, çelişkilerin azalması ve değişikliklerin izlenebilir kalmasıyla değerlendirilmelidir. Bir node’un sorumlusu, kaynak sayfası ve güncelleme tetikleyicisi biliniyorsa teknik ekip ile içerik ekibi aynı gerçeği yönetebilir. Bu düzen, yeni bir sayfa türü veya eklenti devreye girdiğinde kontrolün baştan kurulmasını da önler.
İlk denetimde sitenin ürettiği bütün JSON-LD bloklarını, global entity @id değerlerini ve bu node’ların teknik sahiplerini tek envanterde toplayın. Çelişkiler görünür hale geldiğinde hangi kodun kaldırılacağı, hangi bilginin içerikte düzeltilmesi gerektiği ve hangi değişikliklerin yeniden test tetikleyeceği somutlaşır.
Tarama, indeksleme, canonical ve yapılandırılmış veri kontrollerinin birlikte yönetimi için teknik SEO çalışması sayfasını kullanabilirsiniz.
Yayın tarihi: | Güncelleme tarihi:
