DurumKod Var, SEO Altyapısı Yok
Yeni kurulan bir platform, geliştirme sürecini tamamlayıp yayına hazırlanırken teknik SEO yapılandırması gündemde yoktu. Bu oldukça yaygın bir tablo: ürün önce çalışır hale getirilir, ardından “SEO’ya bakarız” denir. Oysa bu kararın maliyeti ilerleyen dönemde katlanarak geri döner.
Site incelendiğinde tablo netti: robots.txt yoktu, sitemap yoktu, meta etiketlerin büyük kısmı sayfalarda ikişer kez tanımlıydı, JavaScript konsolunda üretim ortamında bulunmaması gereken uyarılar vardı ve frontend bağımlılıklarından biri site performansını baştan aşağı etkiliyor olabilecek şekilde kurulmuştu.
GörevTemeli Sağlam Atmak
Yayın öncesinde yapılan bir teknik SEO denetimi, sonradan yapılacak onlarca saatlik temizlik çalışmasından daha değerlidir. Buradaki görev net bir altyapı değerlendirmesi yapmak, her sorunun etkisini sınıflandırmak ve geliştirici ekibin uygulayabileceği somut bir eylem listesi üretmekti.
YapılanlarKüçük Görünen, Büyük Etkisi Olan Sorunlar
Googlebot’a Giriş İzni Verilmemiş, Harita Çizilmemiş

robots.txt dosyası yoktu. Bu, arama motoru botlarının dashboard sayfası ve statik varlıklar dahil sitenin her dizinine serbestçe girebildiği anlamına geliyordu. Kullanıcıya özel panel sayfalarının bot tarafından taranması hem tarama bütçesi israfı hem de potansiyel güvenlik riski oluşturuyordu.
Sitemap da yoktu. Yeni ve henüz backlink kazanmamış bir site için bu özellikle kritik bir eksik; Google’ın diğer sayfaları keşfetme ve önceliklendirme hızı doğrudan etkileniyordu.
Her iki dosya da hazırlandı, uygun yapılandırmayla yerleştirildi ve Google Search Console üzerinden gönderim gerçekleştirildi.
Meta Etiketler Çakışıyor, Tarayıcı Hangisini Alacak?

charset, viewport ve description etiketlerinin her biri <head> içinde iki kez tanımlanmıştı. Aynı zamanda geçerli bir HTML standardı olmayan <meta name="title"> etiketi tüm sayfalarda mevcuttu ve Google tarafından işlenmiyor.
Bu yapıda Google’ın hangi description’ı snippet olarak seçeceği belirsizleşiyor. Arama sonuçlarında görünen başlık ve açıklama rastgele bir seçimin ürünü olabiliyor. Tüm sayfalar temizlendi, her meta etiketi tek kez ve doğru sırayla tanımlandı.
Open Graph Hatası: Sosyal Paylaşımda Favicon Gösteriliyor
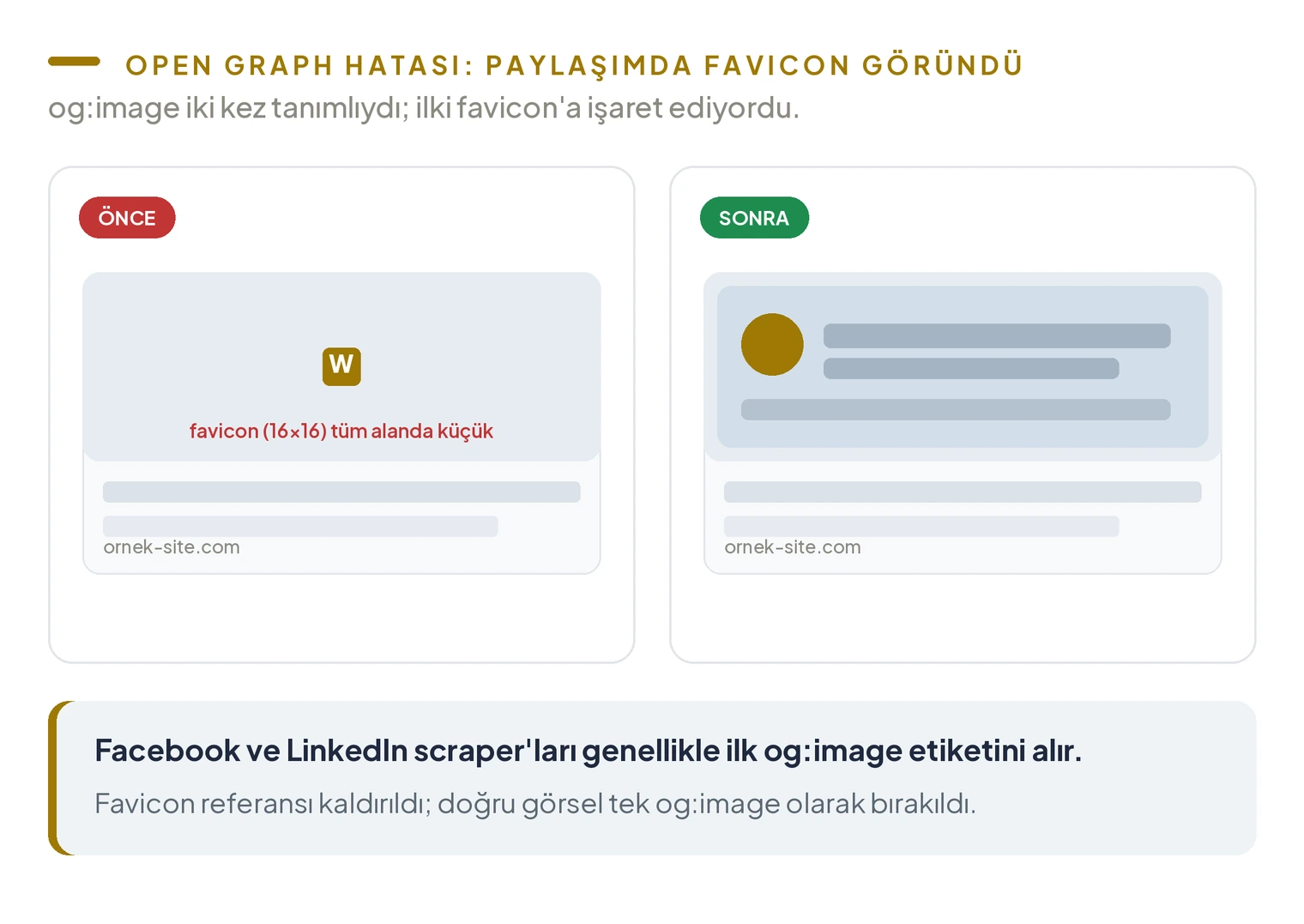
og:image etiketi iki kez tanımlıydı. İlki favicon dosyasına, ikincisi doğru görsele işaret ediyordu. Facebook ve LinkedIn gibi platformların scraper’ları genellikle ilk etiketi alır; bu durumda paylaşımlarda sitenin tam görseli yerine küçük bir favicon görünüyordu. Favicon referansı kaldırıldı.
JavaScript Konsolu: İki Farklı Uyarı, İki Ayrı Sorun

GSC Canlı Test çıktısında iki kritik konsol uyarısı görünüyordu.
Birincisi bir CSS framework’ünün production ortamında CDN üzerinden yüklenmesiydi. Bu kurulum, tarayıcının tüm utility sınıflarını çalışma zamanında parse etmesi anlamına geliyor ve dosya boyutu 350 KB’ın üzerine çıkabiliyor. Production build alındığında aynı çıktı 5 ile 15 KB arasına iniyor. Core Web Vitals metriklerini doğrudan etkileyen bu farkın LCP ve TBT skorlarına yansıması kaçınılmaz.
İkincisi bir kimlik doğrulama kütüphanesinin aynı sayfada iki kez yüklenmesiydi; biri <head> içinde, biri <body> sonunda. Bu çift yükleme konsolda “birden fazla istemci örneği tespit edildi” uyarısı üretiyordu ve tarayıcıda tanımsız davranışlara yol açabilecek bir yapıydı. Body sonundaki tekrarlayan satır kaldırıldı.
URL Tutarsızlığı ve Logo Linkleme Hatası
Aynı sayfa için .html uzantılı ve uzantısız iki farklı URL kullanılıyordu. Canonical etiketi bir versiyona, iç linkler başka bir versiyona işaret ediyordu. Bu tutarsızlık Google’ın iki ayrı sayfa olarak değerlendirme riskini taşıyordu. Sunucu taraflı 301 yönlendirmesiyle standart URL belirlendi, canonical ve sitemap bu URL’e hizalandı.
Alt sayfalarda logo href="#" olarak bırakılmıştı. Bu, kullanıcı logoya tıkladığında ana sayfaya dönmek yerine sayfanın üstüne scroll yapması demek. Hem erişilebilirlik standardı hem de SEO açısından logo her zaman ana sayfaya yönlendirmelidir.
Güvenlik: Dashboard Sayfası Botlara Açık
Kullanıcı paneli yalnızca JavaScript yönlendirmesiyle korunuyordu. HTML dosyasının kendisi robots.txt olmadığı için botlar tarafından erişilebilir durumdaydı. robots.txt yapılandırmasında bu dizin açıkça engellendi.
SonuçSağlam Zemin, Sıfır Teknik Borçla Başlangıç
Denetim sonunda 6 kritik, 7 orta öncelikli bulgu raporlandı ve öncelik sırasına göre geliştirici ekibe teslim edildi. Kritik bulgular kısa sürede kapatıldı.

Yeni bir platform için bu çalışmanın değeri basit: daha baştan biriken teknik borç olmadan büyümeye başlamak. Aylarca trafik üretip sonra “neden indekslenmiyoruz” sorusunu sormak yerine, arama motoru altyapısı doğru kurulmuş, GSC temiz ve yapılandırılmış, performans riskleri baştan tanımlanmış bir platform olarak yola çıkıldı.
